One of the initial limitations of Large Language Models (LLMs) relies on the limited space they were trained on. So despite the capabilities those models exhibite, they can only generate text based on the universe of written communications used to train that particular model. So how can we use those LLMs to work with unseen data?
Retrieval Augmented Generation
LLMs are models especialized on text prediction, they can be seen as the evolved form of the autocomplete features of our keyboards. They are very good predicting text because of advances in the Natural Language Processing (NLP) techniques and modelling especially with the transformers architecture 1. They are so good because there are plenty of written examples that were used to train those models, so if you start writing something (a prompt) those models can predict efficiently how you can continue that text. In simple terms you can see an LLM as a black box that completes text using a prompt.
A very useful application of those models implies completion of that text using a very delimited context instead of using the whole universe of texts used in the training processes. That is precisely the focus of the Retrieval Augmented Generation (RAG). RAG relies on providing a set of text to retrieve important context, then complete (augment) the text, generating a very specific response that uses the context provided.
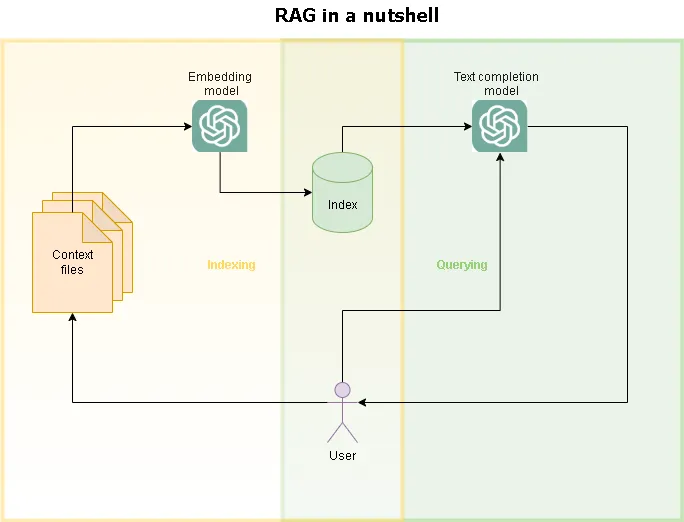
Indexing phase
In the indexing phase of a RAG pipeline, the primary goal is to construct a context base that an LLM can leverage to complete its tasks effectively. But what does it mean to build this context base? Simply put, it involves converting raw text into a format that is machine-friendly and can be efficiently retrieved when needed.
To achieve this, a common approach is to use embeddings, which are vectorized representations of the meaning or semantics of a piece of text. Embeddings allow us to capture the essence of words, sentences, or entire documents in numerical form, enabling machines to process and compare them mathematically. These vectors reside in a high-dimensional space where similar meanings are mapped closer together, facilitating tasks like similarity searches.

The transformation of text into embeddings is a well-established NLP technique. It relies on an embedding model, a specialized neural network designed to encode text into its corresponding vector representation. These models are often pre-trained on vast amounts of data and optimized to preserve semantic relationships, making them an essential component for indexing in modern RAG pipelines.
Query phase
In the querying phase the goal is to retrieve the most relevant information from the index to construct an accurate and context-rich answer. The index, built during the previous phase, acts as the knowledge base. However, it’s critical to retrieve only the information that is most relevant to the given prompt, avoiding unnecessary or irrelevant data that could dilute the quality of the response.
To achieve this, embeddings play a central role. By applying distance metrics (such as cosine similarity or Euclidean distance), we can identify which indexed vectors are nearest to the query embedding, essentially selecting the most relevant pieces of context. Once retrieved, this context is appended to the prompt and provided to the LLM, enabling it to generate a response that is not only more accurate but also augmented with specific information.
Quick implementation
RAG applications are quite common nowadays, so it is important to take a brief look at the tools that can help you implement this type of application. The cutting edge approaches rely on the usage of a well known framework for RAG implementations llama-index and on the most used LLMs provider OpenAI through an API key.
The first step would be installing the dependencies on python.
pip install llama-index
And setting up an environment variable to hold the API KEY provided from openAI:
export OPENAI_API_KEY=<your-api-key-string-here>
Then you can create a notebook to start creating the most simple RAG implementation. In that notebook import the llamaindex modules by:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
Then you can start loading documents from a custom data folder:
documents = SimpleDirectoryReader("data").load_data()
Documents are the basic way to hold pieces of texts, they are the unit of information in llamaindex. The next step would create the index from them:
index = VectorStoreIndex.from_documents(documents)
Once the index is built an engine to query it must be created, that engine can serve as the interface between the index, the LLM and an user asking questions.
query_engine = index.as_query_engine()
Then you can start wsking questions by:
response = query_engine.query("Some question about the data should go here")
print(response)
And thats it! You can start asking questions using your own files with an LLM!
Photo by Markus Winkler from Pexels